
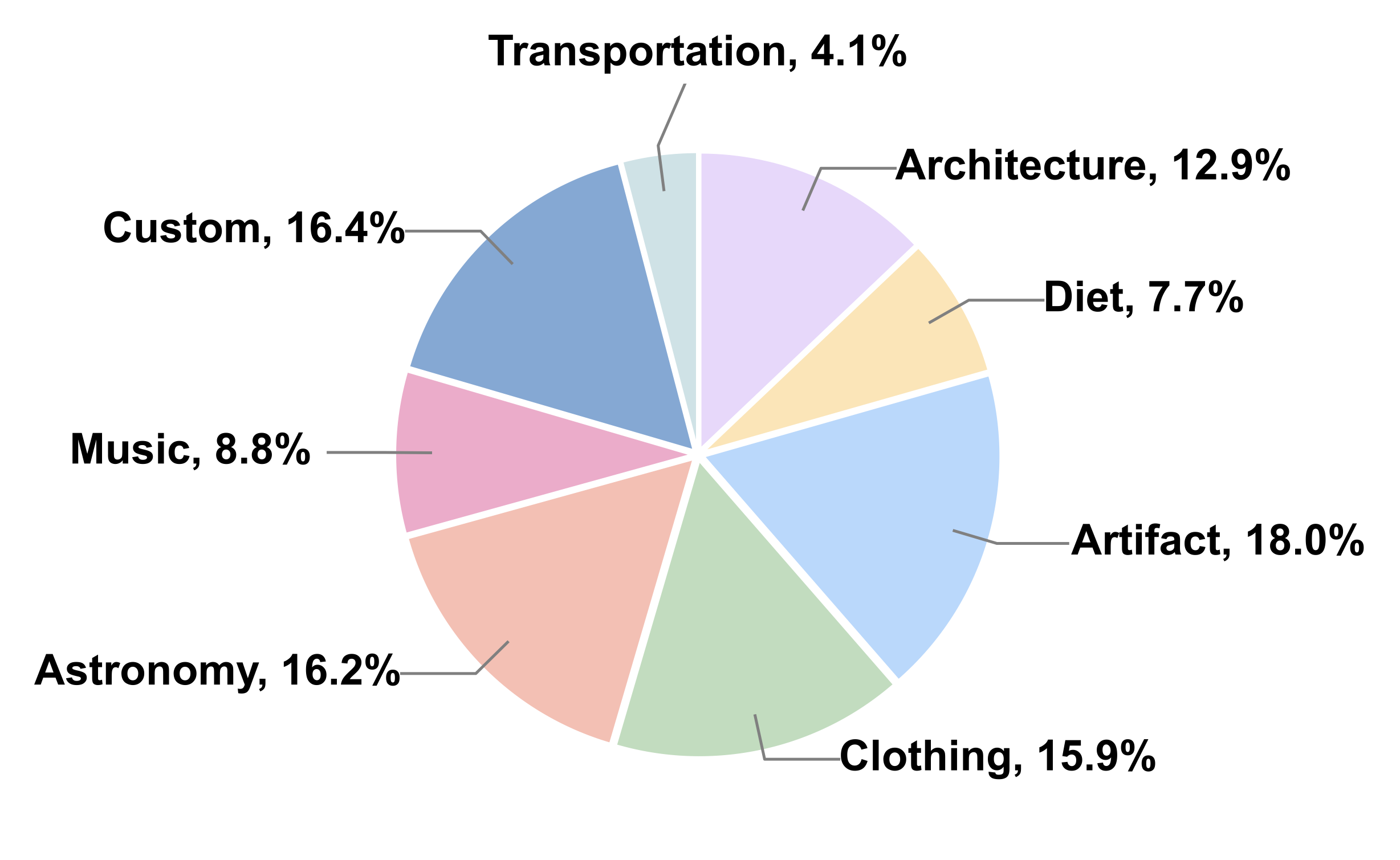
Samples of TCC-Bench. TCC-Bench has eight domains: Astronomy, Music, Custom, Architecture, Transportation, Diet, Clothing and Artifact.
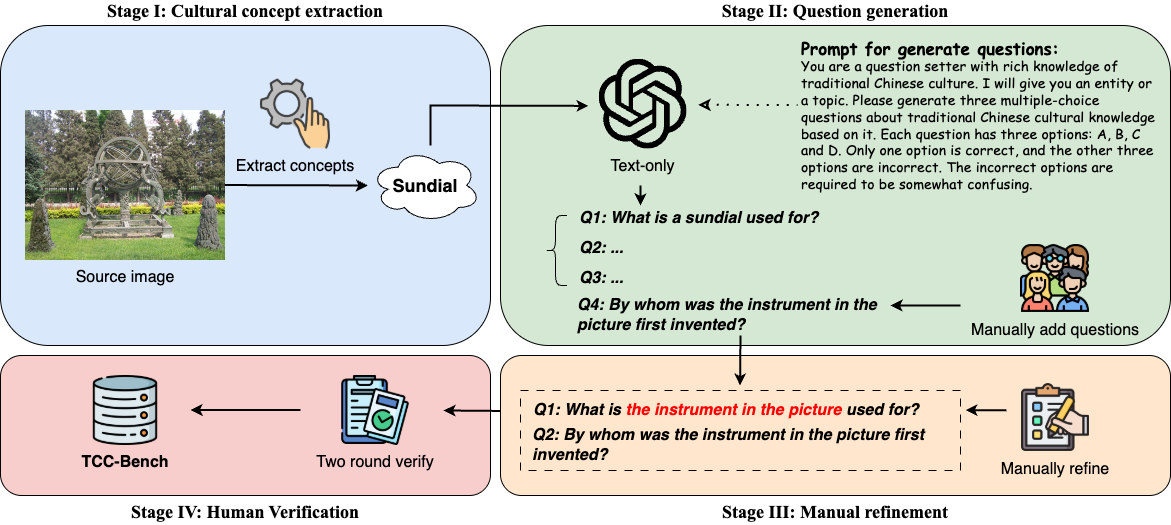
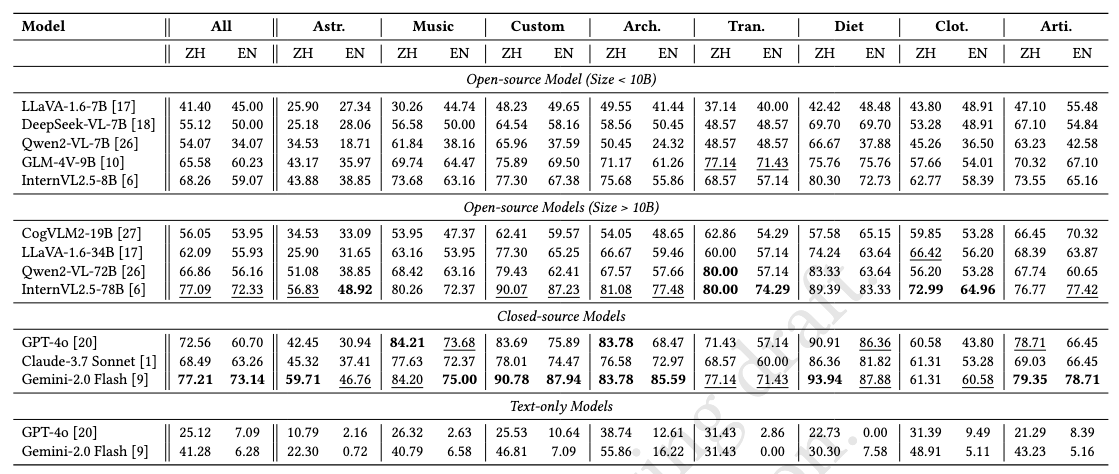
We present the Traditional Chinese Culture understanding Benchmark, TCC-Bench, a bilingual (i.e., Chinese and English) Visual Question Answering (VQA) benchmark specifically designed to evaluate the capabilities of MLLMs in understanding traditional Chinese culture. We customize eight knowledge domains that encompass key aspects of traditional Chinese culture. Moreover, the images within TCC-Bench are curated from museum artifacts, depictions of everyday life, comics, and other culturally significant materials, ensuring both visual diversity and cultural authenticity. Moreover, we introduce a semi-automated question generation method that reduces manual effort while ensuring the acquisition of high-quality data.




@misc{xu2025tccbenchbenchmarkingtraditionalchinese,
title={TCC-Bench: Benchmarking the Traditional Chinese Culture Understanding Capabilities of MLLMs},
author={Pengju Xu and Yan Wang and Shuyuan Zhang and Xuan Zhou and Xin Li and Yue Yuan and Fengzhao Li and Shunyuan Zhou and Xingyu Wang and Yi Zhang and Haiying Zhao},
year={2025},
eprint={2505.11275},
archivePrefix={arXiv},
primaryClass={cs.MM},
url={https://arxiv.org/abs/2505.11275},
}